
How do you handle a scenario where everything (figuratively) is on fire and it’s up to you to make sure your team gets it extinguished? This post offers a glimpse into how our Cyber Incident Response Team (CIRT) fought a recent flare-up in Emotet infections by taking a step back from the mass of alerts to devise a proactive strategy for automation. Our hope is that this write-up may spark some ideas for you when something similar happens in your environment.
Threat Analysts and First Responders
At a conceptual level, the job of a threat analyst is not much different than that of an emergency first responder. A key part of the response is triage. It’s critical to take a step back from the noise and chaos to identify the areas of immediate concern and the best strategic ways to move forward.
Most security teams have multiple people who will recognize when a problem is getting out of control. However, you also need at least one person to act as an “incident commander” or operations lead—stepping away from the fire, so to speak, to develop the mitigation plan. This person needs to have a grasp on the internal and external resources that can be called on for help and should understand that there are times when you have to take people out of the immediate fight in order to work on longer term, more impactful solutions.
Case Study: Fighting a Rapidly Spreading Emotet Outbreak
Strategic triage planning looks great on paper and in theory, but how do you apply it in the real world? Well, that’s exactly the question our CIRT faced recently when we found ourselves responding to multiple Emotet outbreaks. Emotet is nothing new, and Red Canary has helped customers respond to Emotet infections before. However, we hadn’t seen such a widespread outbreak until one of our incident response partners started bringing us surge work with customers that were utterly overrun with the malware. It was almost immediately apparent that these engagements were eating up a disproportionate amount of analyst time, which is precisely why we needed to develop a new triage plan.
For those of you who don’t know what Emotet is, we’ll save you the trouble of Googling: it’s a trojan that is often delivered via spam or phishing emails which contain benign-looking but malicious attachments (PDFs, Word documents, etc.). After the system is infected, network traffic is intercepted via the web browser to steal financial information, credentials, and other sensitive data.
In the cases we were dealing with, Emotet was bundled with another strain of malware called Trickbot, which amplified the scope of the problem by using the server message block (SMB) protocol to spread laterally on the affected networks and rapidly infect other machines. To make matters even more interesting, the Emotet binary would rewrite itself to the host in instances where it detected mitigation efforts by local antivirus. So now we had a trojan worming its way around networks and rewriting itself when it sensed the presence of antivirus. What should we do to address it?

Sometimes the simplest plans are the most effective. First, we built a new detector to identify the behaviors that we were seeing 100 percent of the time. This way, we wouldn’t have to keep digging into the telemetry data on our more broad detectors. After that, we worked with our incident response partner (who was hands-on in the infected environments) to take advantage of our new Automate product. In this instance, we used Red Canary Automate to develop automated playbooks that worked the Carbon Black Live Response API to start banning the various binary hashes we were identifying.
Having the ability to remotely ban bad hashes was very important because the customer had limited IT resources; unfortunately, it did little to alleviate the monotony that our detection engineers and analysts were experiencing in responding to infections on each individual endpoint.
Enter the Detection Bots…

Some time ago, we developed a strategy to automate the most remedial and tedious malware detections out of our operations. We call these Detection Bots. At a very high level, the Detection Bots do exactly what a human analyst would do in response to events generated from a specific detector in our arsenal. Up until this point, the Detection Bots were mainly used to quickly identify behaviors that corresponded with potentially unwanted programs (PUPs). However, the broader plan was always to make the Detection Bots more robust so that we could increasingly automate the detection of known bads.
The way we see it, there is no value in our detection engineers wasting their time repeatedly identifying and reporting the same behaviors; that is exactly the type of work a computer should be doing. These Emotet outbreaks offered us a great opportunity to put this idea to the test and figure out how to make it work.
We configured one of the Detection Bots to identify when a process matched the following criteria: (a) was executed from the parent process “services.exe”; and (b) had a name consisting of at least 6 characters with either all digits or digits and the letters A through G. This was finding Emotet binaries perfectly, but now we had a new problem: we flooded ourselves with new indicators of compromise (IOC) as the Detection Bots and humans continued to find more malicious binaries.
Up until this point, the Detection Bots had relied solely on behavioral detectors in order to take action. When we find malicious binaries, we mark them as an IOC—not just to make our customers aware it’s bad, but also to create an internal database of known bad binaries. Part of our event generation process is for telemetry data to pass through a check to see if the binary executing or being written matches a known IOC. If our engine detects a match on a bad binary, then it raises an event. This happens so quickly that binary-based detectors will almost always beat any type of behavioral detector in the race to event generation. This was diminishing the effectiveness of the Detection Bots as we continued to find additional Emotet binaries. As such, we decided to update the Detection Bots so they would be able to trigger off of IOCs. Almost immediately after making this change, we had the fire under control.
Before and After
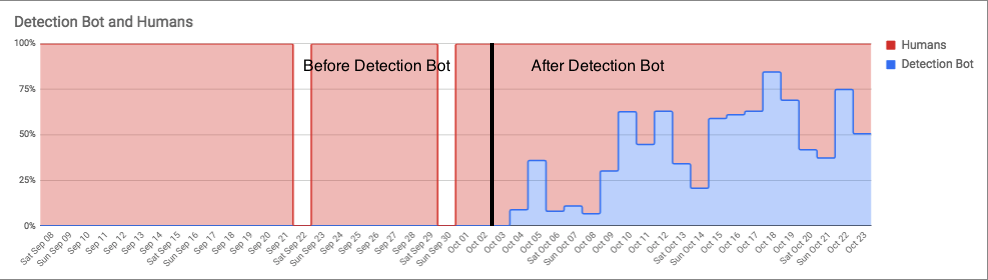
The graphs below illustrate the difference before and after the Detection Bots. As you can see, our CIRT was inundated with thousands of malicious software detections during our surge work with Emotet. The vertical black line marks where we began to automate ourselves out of the mess via the Detection Bots platform.
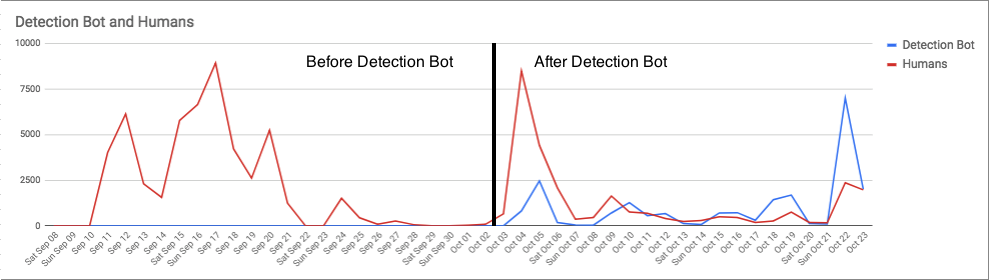
In the graph below, you can see just how much work the Detection Bots performed relative to the amount of work performed by human analysts. As a side note, you’ll notice fairly steep valleys in both graphs over the weekends, when the customers’ networks were largely offline. Keep in mind that not much changed in the amount of ingress events we were receiving from these Emotet infected environments—instead, the vast majority of related detections being pushed out were now done by the Detection Bots.
 Key Takeaways
Key Takeaways
 Key Takeaways
Key TakeawaysSo what can we all learn from this? The most important and broadest lesson is a simple reminder of how beneficial it can be to take a step back and sacrifice short-term progress in favor of a longer-term or even (fingers crossed) permanent solution. For the first few days of working with these outbreak scenarios, we were simply suffering through it and expecting that mitigation efforts would soon kick in to lessen the load. When it became obvious that was not going to happen, we decided it was worth enduring a short-term negative impact to operations while we figured out a long-term solution.
The best part about the long-term solution we devised is that it’s not only applicable to the next Emotet infection, but the next Bitcoin miner worm, and many future outbreaks we are likely to encounter as we move forward. We all have areas of our operation that require growth and improvement. The key is to identify the basic needs, accept the short-term growing pains, and persevere in order to enjoy the long-term benefits.

Related Articles
The dual-use dilemma: Rethinking detection for remote access tool abuse